
배열과 인덱스
배열과 같이 여러 데이터(자료)를 구조화해서 다루는 것을 자료구조라고 한다.
자바는 배열 뿐 아니라 컬렉션 프레임워크라는 다양한 자료구조를 제공한다.
그 전에 먼저 기본이 되는 자료구조인 배열의 특징에 대해서 알아보자
public class ArrayMain1 {
public static void main(String[] args) {
int[] arr = new int[5];
System.out.println("==index 입력: 0(1)==");
arr[0] = 1;
arr[1] = 2;
arr[2] = 3;
System.out.println(Arrays.toString(arr));
// index 변경: 0(1)
System.out.println();
System.out.println("==index 변경: 0(1)==");
arr[2] = 10;
System.out.println(Arrays.toString(arr));
System.out.println("==index 조회: 0(1)==");
System.out.println("arr[2] = " + arr[2]);
System.out.println("==배열 검색: 0(n)==");
System.out.println(Arrays.toString(arr));
int value = 10;
for (int i = 0; i < arr.length; i++) {
System.out.println("arr[" + i + "]: " + arr[i]);
if (arr[i] == value) {
System.out.println(value + "찾음");
break;
}
}
}
}
배열에서 자료를 찾을 때 index를 사용하면 매우 빠르게 자료를 찾을 수 있다. 이보다 더 빠르게 찾을 순 없다.
인덱스를 통한 입력, 변경, 조회의 경우 한번의 계산으로 자료의 위치를 찾을 수 있다.

arr[2]에 있는 자료를 찾는다고 가정할 때, 배열은 메모리상에 순서대로 붙어서 존재한다.
int는 4byte를 차지하기 때문에, 배열의 시작위치인 x100부터 자료의 크기인 4byte와 인덱스를 곱하면
원하는 메모리 위치를 찾을 수 있다.
위 방법으로 한번의 계산으로 매우 효율적으로 자료의 위치를 찾을 수 있다.
배열의 검색
배열에 들어있는 데이터를 찾는것을 검색이라고 한다.
배열의 검색은 배열에 들어있는 데이터를 하나하나 비교해야한다. 따라서 인덱스를 사용해서 한번에 찾을 수 없다.
그렇기에 배열의 크기가 클 수록 시간이 오래 걸리게 된다.
배열의 크기가 n이면 연산도 n만큼 필요하게 되는 것이다.
빅오 표기법
빅오(Big O) 표기법은 알고리즘 성능을 분석할 때 사용하는 수학적 표현 방식이다.
알고리즘이 처리해야할 데이터의 양이 증가할 때 그 알고리즘이 얼마나 빠르게 실행되는지 나타낸다.
중요한 점은 빅오 표기법은 정확한 실행 시간을 계산하는것이 아닌, 데이터 양에 따른 성증의 변화 추세를 이해하는 것이다.

O(1) - 상수 시간: 입력 데이터의 크기와 상관없이 알고리즘의 실행시간이 일정 (인덱스 사용)
O(n) - 선형 시간: 실행 시간이 데이터의 크기에 비례하여 증가 (배열 검색, 모든 요소 순회하는 경우)
O(n²) - 제곱 시간: 실행 시간이 입력 데이터의 크기의 제곱에 비례하여 증가 (이중 루프의 경우)
O(log n) - 로그 시간: 실행 시간이 데이터의 크기의 로그에 비례하여 증가 (이진 탐색)
O(n log n) - 선형 로그 시간: 다양한 효율적인 정렬 알고리즘 등
빅오 표기법은 매우 큰 데이터를 입력한다고 가정했을 때, 데이터 양의 증가에 따른 성능 변화의 추세를 비교하는데 사용한다.
다시한번 말하지만 정확한 성능 비교를 위해서 사용하는 것이 아니다. 그러므로 추세를 보는데 상수가 크게 의미 없다.
예를 들어 O(n + 2), O(n / 2) 일 경우에 차트의 모양이 당연히 달라지겠지만, 크게 차이가 나지 않기 때문이다.
빅오 표기법은 보통 최악의 상황을 가정해서 표기한다. 물론 최적, 평균, 최악의 경우로 나누기도 한다.
최적: 배열의 첫번째 항목에서 바로 값을 찾으면 / O(1)
최악: 마지막 항목에 있거나 항목이 없는 경우 전체 요소 순회 / O(n)
평균: 평균적으로 보통 중간쯤 데이터를 발견하게 된다. 이 경우 O(n/2)지만 상수를 제외하므로 O(n)
정리
인덱스 사용 O(1)
순차 검색 O(n)
인덱스를 사용할 수 있으면 최대한 사용하자.
배열 - 데이터 추가
배열에 데이터를 추가 예시
- 배열의 첫번째 위치에 추가

기존 데이터들을 모두 오른쪽으로 한칸 씩 밀어서 추가할 위치를 확보해야 한다.
이때 배열의 오른쪽 부터 밀어야 데이터를 유지할 수 있다. (왼쪽부터 밀면 값이 중복됨)
대입하는 과정들은 반복된다.
private static void addFirst(int[] arr, int newValue) {
for (int i = arr.length - 1; i > 0; i--) {
arr[i] = arr[i - 1];
}
arr[0] = newValue;
}
첫번째 위치를 찾는데 인덱스를 사용하므로 O(1)
데이터의 크기만큼 한칸씩 이동해야하므로 O(n)
O(1 + n) -> O(n)
- 배열의 중간 위치에 추가
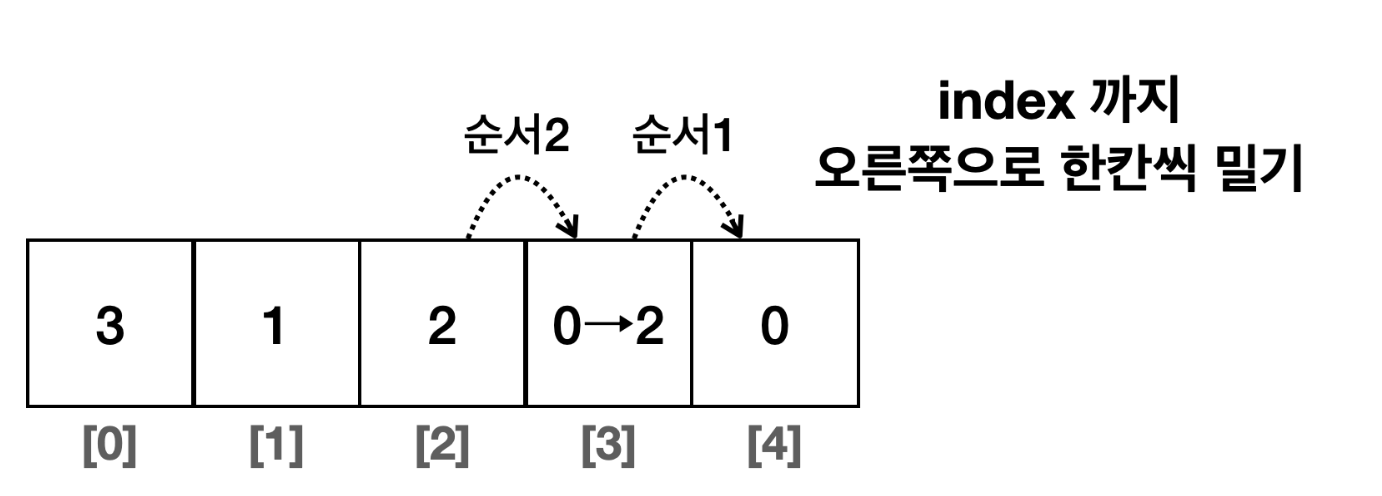
index부터 시작해서 데이터들을 오른쪽으로 한칸씩 밀어야 한다.
대입하는 과정들은 반복된다.
private static void addAtIndex(int[] arr, int index, int value) {
for (int i = arr.length - 1; i > index; i--) {
arr[i] = arr[i - 1];
}
arr[index] = value;
}
배열의 위치를 찾는데 O(1)
index의 오른쪽에 있는 데이터 한칸씩 이동 O(n)
O(1 + n/2) -> O(n)
- 배열의 마지막 위치에 추가
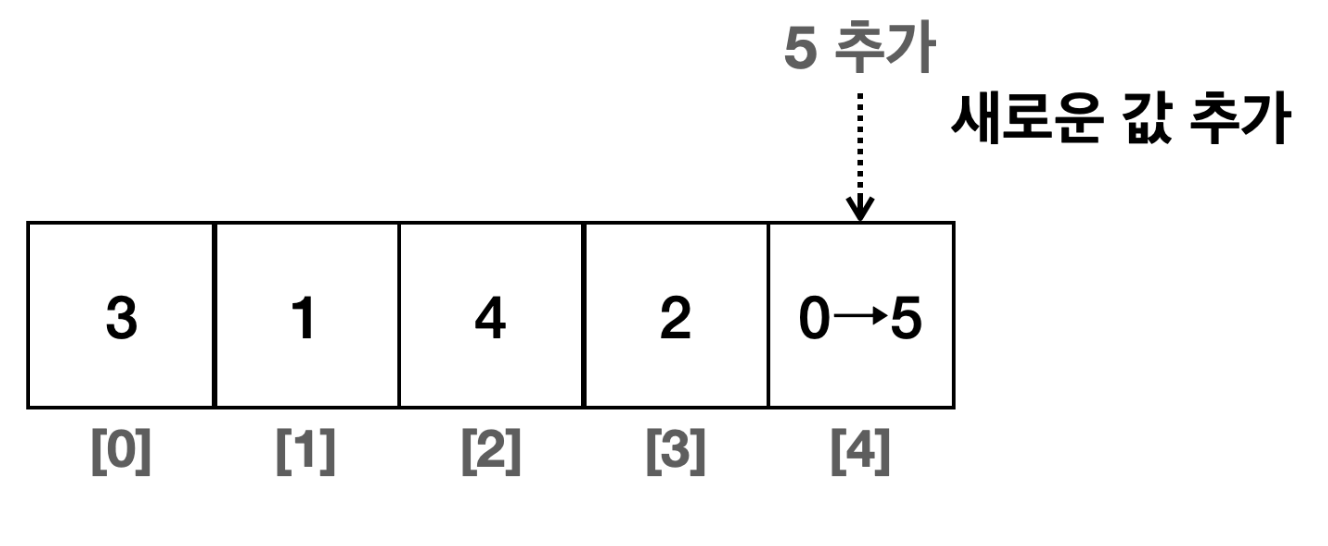
데이터를 이동하지 않아도 된다. 단순히 값만 입력하면 된다.
private static void addLast(int[] arr, int newValue) {
arr[arr.length - 1] = newValue;
}
배열이 이동하지 않고 .length로 마지막 인덱스에 바로 접근할 수 있음. 배열을 이동하지 않으므로 O(1)
배열은 가장 기본적인 자료구조이다. 특히 인덱스를 사용할 때 최고의 효율이 나온다.
하지만 큰 단점이 존재하는데 배열의 크기를 생성하는 시점에 미리 정해야하기 때문이다.
언제 얼마의 배열이 필요할 지 예측하기 어려운 것이다. 그렇다고 많은 배열을 생성하면 메모리 낭비가 된다.
List
순서가 있고, 중복을 허용하는 자료구조를 리스트라고 한다.
배열과 리스트는 구분해서 이야기한다. 리스트는 배열보다 유연한 자료구조로, 크기가 동적으로 변할 수 있다.
package collection.array;
import java.util.Arrays;
public class MyArrayListV1 {
// MyArrayListV1을 생성할 때 사용하는 기본 배열의 크기
private static final int DEFAULT_CAPACITY = 5;
private Object[] elementData;
private int size = 0;
public MyArrayListV1() {
elementData = new Object[DEFAULT_CAPACITY];
}
public MyArrayListV1(int initialCapacity) {
elementData = new Object[initialCapacity];
}
public int size() {
return size;
}
// 리스트에 데이터를 추가한다. 추가시 size 증가
public void add(Object e) {
elementData[size] = e;
size++;
}
// 인덱스에 있는 항목을 조회
public Object get(int index) {
return elementData[index];
}
// 인덱스에 있는 항복을 변경
public Object set(int index, Object element) {
Object oldValue = get(index);
elementData[index] = element;
return oldValue;
}
// 검색 메서드. 리스트를 순차 탐색해서 인수와 같은 데이터가 있는 인덱스 위치 반환
public int indexOf(Object o) {
for (int i = 0; i < size; i++) {
if (o.equals(elementData[i])) {
return i;
}
}
return -1;
}
public String toString() {
return Arrays.toString(Arrays.copyOf(elementData, size)) +
"size =" + size + ", capacity = " + elementData.length;
}
}
public class MyArrayListV1Main {
public static void main(String[] args) {
MyArrayListV1 list = new MyArrayListV1();
System.out.println("== 데이터 추가 ==");
System.out.println(list);
list.add("a");
System.out.println(list);
list.add("b");
System.out.println(list);
list.add("c");
System.out.println(list);
}
}
순차적으로 데이터가 들어가는 모습이다.
System.out.println("list.indexOf(\"c\") = " + list.indexOf("c"));
System.out.println("list.set(2, \"z\") = " + list.set(2, "z"));
System.out.println(list);
indexOf()를 사용해 c의 위치를 찾고, set()을 사용해 2번 인덱스의 데이터를 z로 변경했다.
여기서 5개 이상의 데이터를 입력하게 되면, OutOfBoundException이 발생한다.

리스트는 동적으로 저장할 수 있는 크기가 커지는 것이다. 데이터의 크기가 동적으로 변경할 수 있도록 해보자
동적 배열
public void add(Object e) {
// 코드 추가
if (size == elementData.length) {
grow();
}
elementData[size] = e;
size++;
}
private void grow() {
int oldCapacity = elementData.length;
int newCapacity = oldCapacity * 2;
// 배열을 새로 생성 후 기존 배열을 새로운 배열에 복사
elementData = Arrays.copyOf(elementData, newCapacity);
// Object[] newArr = new Object[newCapacity];
// for (int i = 0; i < elementData.length; i++) {
// newArr[i] = elementData[i];
// }
}
데이터를 추가할 때 리스트의 size가 capacity를 넘어가야하는 상황이라면 더 큰 배열을 만들어서 해결할 수 있다.
size가 capacity에 도달하면, grow() 메서드를 호출해 capacity의 양을 2배로 늘려주고 기존의 배열을 새로운 배열에 복사한다.
Arrays.copyOf()를 사용하면 아래의 주석처리된 코드를 간단하게 구현할 수 있다.

2배 더 큰 capacity를 생성해 elementData가 newCapacity를 참조하게 된다.
그렇게되면 기존에 참조하던 oldCapacity는 더이상 참조하는곳이 없으므로 GC의 대상이 된다.
데이터가 추가될 때마다 하나씩 추가하면 배열을 복사하는 연산이 너무 자주 발생할 가능성이 있다.
위 코드에선 2배씩 증가하지만 일반적인 경우엔 50%씩 증가하는 방법을 사용한다.
MyArrayListV2는 크기가 동적으로 변하는 자료구조이다. 따라서 데이터의 크기를 미리 지정하지 않아도 된다.
MyArrayListV2의 내부에서는 배열을 사용하지만, 이 클래스를 사용하는 개발자들은 이런 부분을 신경쓰지 않아도 된다.
메서드 추가
add(index, data)와 remove(index)를 추가해보자
앞서 만든 add() 메서드는 데이터를 마지막에 추가하기 때문에 기존 데이터를 이동하지 않고 추가할 수 있다.
하지만 중간에 추가하게 될 경우엔 기존 데이터를 한칸씩 이동시켜야 한다.
삭제의 경우도 마찬가지 이다. 마지막의 데이터만 삭제한다면 이동하지 않아도 되지만, 중간의 데이터를 삭제할 경우
기존의 데이터를 한칸씩 이동시켜야한다.
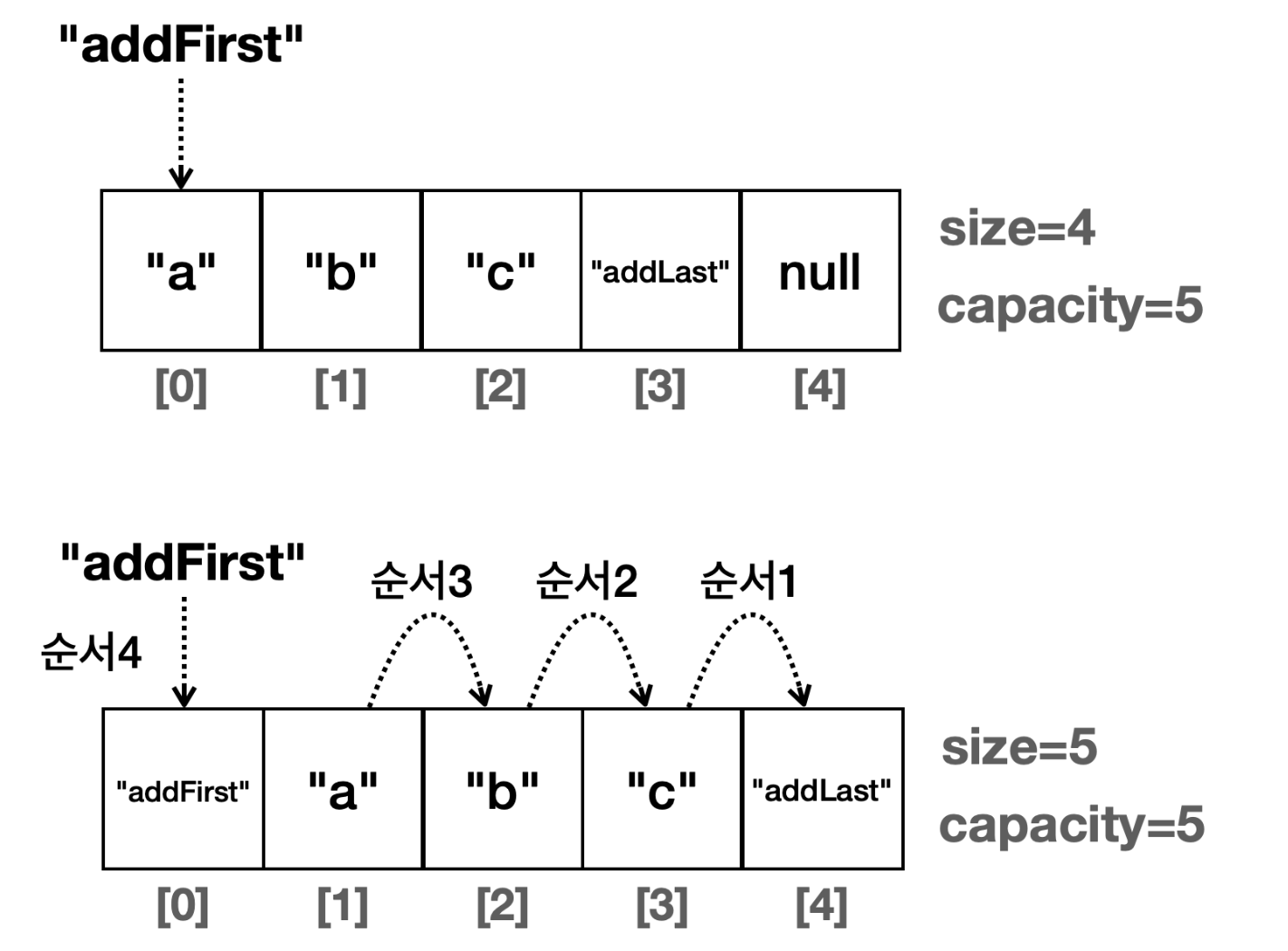
앞에 데이터를 추가한다면 한칸씩 이동되는걸 확인할 수 있다.
public void add(int index, Object e) {
if (size == elementData.length) {
grow();
}
// 데이터 이동
shiftRightFrom(index);
elementData[index] = e;
size++;
}// 코드 추가, 요소의 마지막부터 index 까지 오른쪽 밀기
private void shiftRightFrom(int index) {
for (int i = size; i > index; i--) {
elementData[i] = elementData[i - 1];
}
}
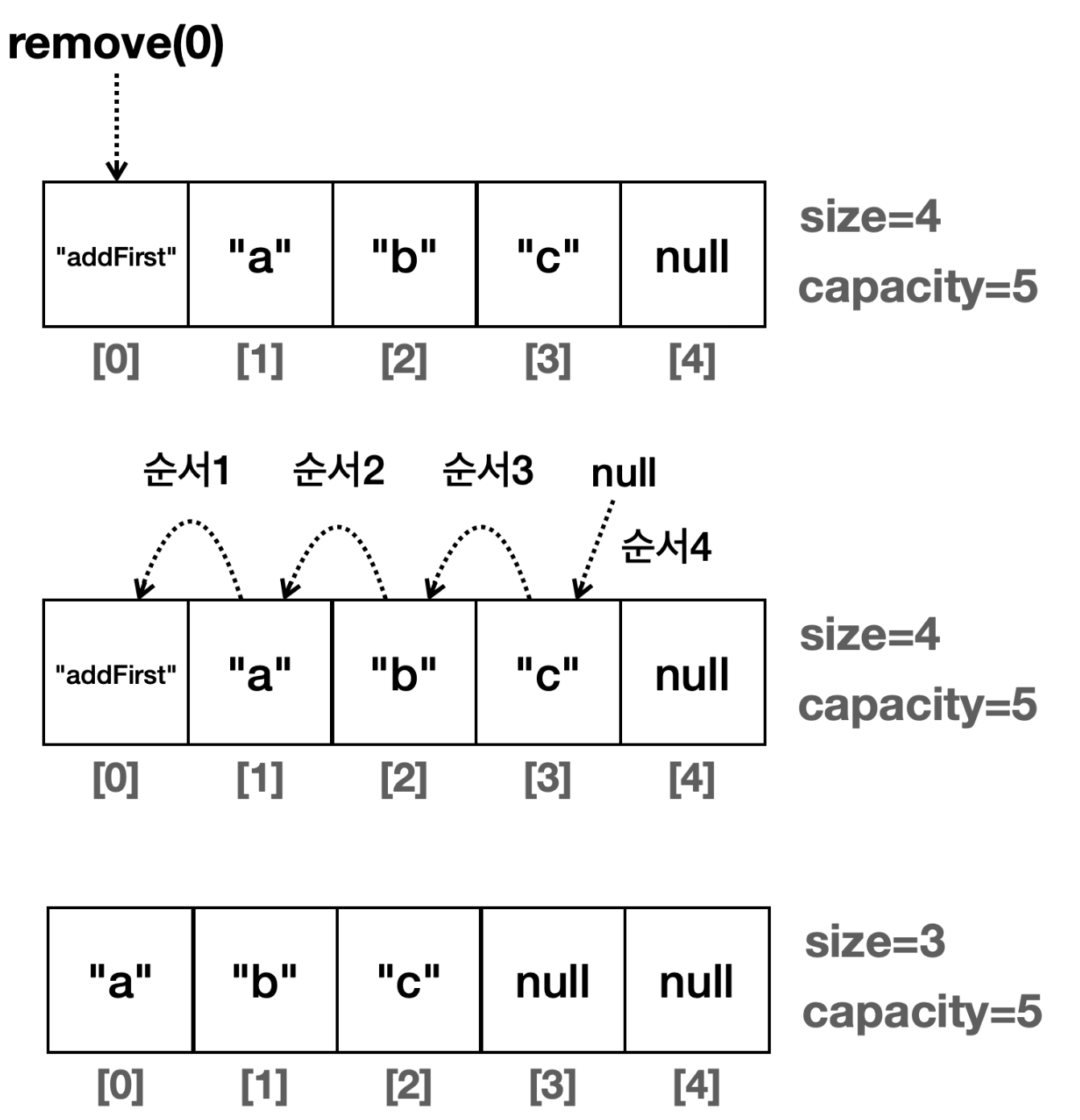
삭제의 경우도 마찬가지로 데이터가 한칸씩 이동한다.
public Object remove(int index) {
Object oldValue = get(index);
shiftLeftFrom(index);
size--;
elementData[size] = null;
return oldValue;
}// 코드 추가 요소의 인덱스부터 마지막까지 왼쪽으로 밀기
private void shiftLeftFrom(int index) {
for (int i = index; i < size - 1; i++) {
elementData[i] = elementData[i + 1];
}
}
우리가 만든 자료구조를 배열 리스트 (ArrayList)라고 한다. List 자료구조를 사용하지만, 내부의 데이터는 배열에 보관하는 것이다.
위에서도 언급했지만
마지막에 추가 O(1) / 앞, 중간에 추가 O(n)
마지막 삭제 O(1) / 앞, 중간에 삭제 O(n)
인덱스 조회 O(1) / 데이터 검색 O(n)
배열 리스트는 마지막에 데이터를 추가하거나 마지막에 있는 데이터를 삭제할 땐 O(1)로 성능이 좋다.
그러나 중간에 데이터를 추가하거나 삭제할 경우 O(n)으로 성능이 나쁘다.
배열 리스트는 보통 데이터를 중간에 추가하고 삭제하기 보다, 데이터를 순서대로 입력하고 (마지막에 추가하고)
순서대로 출력하는 경우에 가장 효율적인 자료구조이다.
제네릭 도입
자료구조에 숫자와 문자처럼 서로 관계없는 여러 데이터 타입을 섞어서 보관하는 일은 거의 없다.
제네릭을 사용하지 않으면 값을 꺼낼 때 Object를 반환하기 때문에 다운캐스팅이 필요하게 되고
정확히 인지하지 못했을 경우 예외가 발생할 수 있다.
MyArrayList들은 Object를 입력 받기 때문에, 아무 데이터나 입력할 수 있고 Object를 반환한다.
따라서 타입 안전성이 떨어지게 된다. 그래서 타입 안정성을 높이기 위해 제네릭을 도입해보자
// 중간 코드 생략
public class MyArrayListV4<E> {
// MyArrayListV1을 생성할 때 사용하는 기본 배열의 크기
private static final int DEFAULT_CAPACITY = 5;
private Object[] elementData;
public MyArrayListV4() {
elementData = new Object[DEFAULT_CAPACITY];
}
// 리스트에 데이터를 추가한다. 추가시 size 증가
public void add(E e) {
// 코드 추가
if (size == elementData.length) {
grow();
}
elementData[size] = e;
size++;
}
// 코드 추가
public void add(int index, Object e) {
if (size == elementData.length) {
grow();
}
// 데이터 이동
shiftRightFrom(index);
elementData[index] = e;
size++;
}
// 인덱스에 있는 항목을 조회
@SuppressWarnings("unchecked")
public E get(int index) {
return (E) elementData[index];
}
// 인덱스에 있는 항복을 변경
public E set(int index, E element) {
E oldValue = get(index);
elementData[index] = element;
return oldValue;
}
// 코드 추가
public E remove(int index) {
E oldValue = get(index);
shiftLeftFrom(index);
size--;
elementData[size] = null;
return oldValue;
}
// 검색 메서드. 리스트를 순차 탐색해서 인수와 같은 데이터가 있는 인덱스 위치 반환
public int indexOf(E o) {
for (int i = 0; i < size; i++) {
if (o.equals(elementData[i])) {
return i;
}
}
return -1;
}
제네릭 타입을 E로 지정 후, add, get, set, remove의 반환타입을 E로 변경했다.
또 indexOf의 파라미터를 E로 변경했다.
public class MyArrayListV4Main {
public static void main(String[] args) {
MyArrayListV4<String> stringList = new MyArrayListV4<>();
stringList.add("a");
stringList.add("b");
stringList.add("c");
String string = stringList.get(0);
System.out.println("string = " + string);
MyArrayListV4<Integer> intList = new MyArrayListV4<>();
intList.add(1);
intList.add(2);
intList.add(3);
Integer integer = intList.get(0);
System.out.println("integer = " + integer);
}
}
이제 stringList는 String 타입만 보관, 조회가 가능하고 intList는 Integer 타입만 보관, 조회가 가능하다.
메서드에서 다운캐스팅 후 리턴하기 때문에 입력만 제대로 들어온다면 예외가 발생할 일이 없다.
그런데 여기서 여전히 Object 타입의 배열을 사용한다. 이유가 무엇일까?
이전에 공부했던 타입 이레이저를 떠올려보면 답이 나온다. 제네릭은 런타임에 타입 정보가 필요한 생성자에 사용할 수 없다.
따라서 모든 데이터를 담을 수 있는 Object 타입을 사용해야 한다.
add() 메서드를 살펴보면 매개변수에 (E e)를 받는다. E 타입의 값만 입력받을 수 있고, E타입으로 다운캐스팅 하는 기능이다.
처음 설계 단계부터 메서드를 정확히 생성하는것이 중요하다. 이때 설계만 정확히 한다면 다운 캐스팅에 대한 문제는 없다.
MyArrayList의 단점
- 정확한 크기를 미리 알지 못하면 메모리가 낭비된다. (위의 그림에 null로 된 부분을 보자)
- 중간에 추가하거나 삭제할 때 비효율적이다. O(n)
'Java' 카테고리의 다른 글
| 컬렉션 프레임워크 - List (1) | 2025.01.13 |
|---|---|
| 컬렉션 프레임워크 - LinkedList (0) | 2025.01.03 |
| 제네릭 (2) (1) | 2024.12.15 |
| 제네릭 (1) (1) | 2024.12.12 |
| 예외 처리 (3) (0) | 2024.12.11 |